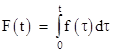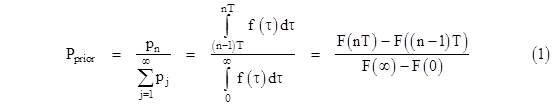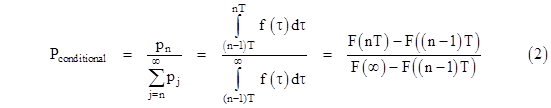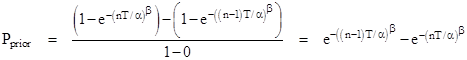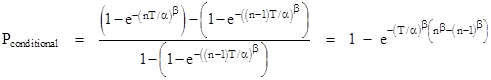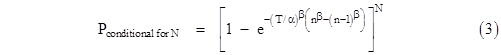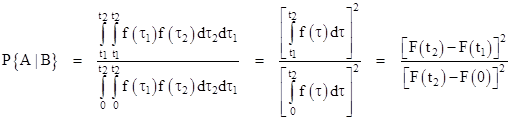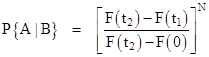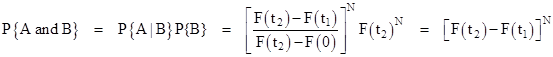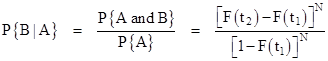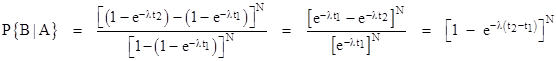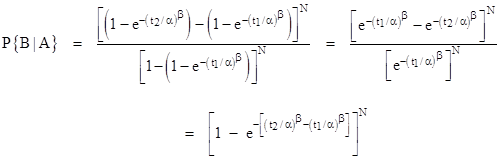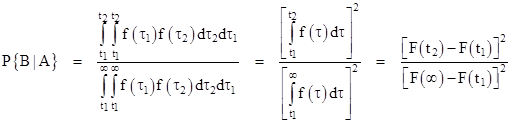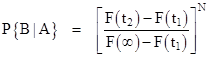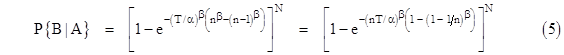|
Prior and Conditional Probabilities |
|
|
|
Consider a single component with a specified failure density distribution f(t), and suppose this component performs a series of discrete missions, each of duration T hours, until the component fails. What is the probability that the component will fail during the nth mission? There are two different ways in which we might interpret this question, depending on whether we want the prior probability or the conditional probability. |
|
|
|
Before the start of the first mission, we can compute the probability that the component will fail during the nth mission. This is called the prior probability. Alternatively, we could wait until the first n–1 missions have been completed, and then, given that the component hasn’t failed during any of those, compute the probability of failure during the next (i.e., the nth) mission. This is a conditional probability, meaning that it is the probability of the component failing during the nth mission given than it does not fail during the first n–1 missions. Bearing in mind that, in general, the probability of a specified outcome represents the ratio of the measure of that outcome divided by the measure of all possible outcomes, it’s clear that the prior and the conditional probabilities will differ, because the set of all possible outcomes is different on the prior basis than on the conditional basis. |
|
|
|
From the prior perspective, let pj for j = 1 to ∞ denote the probability that the component will fail during the jth mission. The sum of all these probabilities is 1, and hence the prior probability of failure during the nth mission is simply pn, which is given by integrating the density function f(t) from t = (n–1)T to nT. In this case the denominator of the probability is 1, corresponding to the complete set of prior possible outcomes, which of course is given by integrating the density function f(t) from t = 0 to ∞. Since we often need to integrate the density function, it’s convenient to define a cumulative probability function |
|
|
|
|
|
|
|
In these terms we can express the prior probability in any of the following equivalent ways |
|
|
|
|
|
|
|
Of course, the denominators of these expressions are each 1. Now, to determine the conditional probability of failure during the nth mission, given that the component does not fail during the first n–1 missions, the numerators are the same, but the denominators must now exclude the first n–1 missions, because they are no longer possible outcomes (by stipulation). Thus we have |
|
|
|
|
|
|
|
As an example, suppose the failures have a Weibull distribution, i.e., we have |
|
|
|
|
|
|
|
for known constants α and β. This can be integrated to give the cumulative probability |
|
|
|
|
|
|
|
Plugging this into the expressions for the prior and conditional probabilities, and noting that F(0) = 0 and F(∞) = 1, we get |
|
|
|
|
|
|
|
and |
|
|
|
|
|
We can immediately generalize this to a system consisting of N identical redundant components, provided the components are all independent. Since the components are independent, the conditional probability of all N components failing during the nth mission, given that none of them failed during the previous missions, is simply the product of the individual probabilities, i.e., |
|
|
|
|
|
|
|
To show how the various prior and conditional probabilities are related, let A denote the event {No components failed at or before the end of the (n–1)th mission}, and let B denote the event {All components failed at or before the end of the nth mission}. We can depict these events on the timeline of component failure as shown below. |
|
|
|
|
|
|
|
The conditional probabilities involving these events are related according to |
|
|
|
|
|
|
|
where the notation “A|B” signifies “A given B”. For convenience, let t1 and t2 denote the times (n–1)T and nT respectively. For a system comprised of N identical components, each with a probability density function f(t) and cumulative distribution F(t), we immediately have |
|
|
|
|
|
|
|
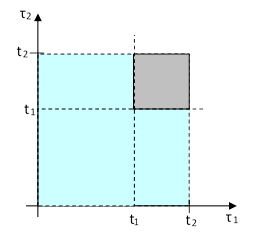
Since the components are independent, the conditional probabilities can be found as described previously, by simply integrating the density for a single component and raising the result to the Nth power. Another way of looking at this, which is sometimes useful for visualizing the space of possible outcomes in N dimensions is to perform the N-fold integrals of the joint probability density over the appropriate regions of the sample space. This is illustrated in the figure below for N = 2. Each point on this plot represents a possible set of failure times τ1 and τ2 for the two components. The probability of the joint outcome falling within any small square region is simply the product of the probabilities of the two individual components falling within the boundaries of that region. Therefore, the joint density is the product f(τ1)f(τ2) of the two densities, and we integrate this over the area to get the (prior) probability of the joint outcome being in any given region. |
|
|
|
|
|
|
|
We should emphasize that, since the components are independent and the boundaries of integration are orthogonal, we can treat each component separately and simply multiply the results together, as we did previously. In that sense, there is nothing new about this joint approach. The joint approach is really only significant for cases when the joint probability density cannot be factored, or when the boundaries of the regions to be integrated are not orthogonal. (See the note on Dual Failures with General Densities for a discussion of one such situation.) Nevertheless, just to show that this joint method reduces to the individual method, note that the conditional probability P{A|B}, i.e., the probability that neither component has failed by time t1 given that both are failed by time t2, is the ratio of the integrals of the gray shaded area to the overall blue+gray area, so we have |
|
|
|
|
|
|
|
Here we’ve made use of the fact that the joint density function is factorable into two independent (and identical) one-dimensional density functions, so the integrals can be evaluated separately and the results multiplied together. The very same analysis applies for N components, i.e., we integrate the joint density function over the appropriate N-dimensional “cubes” with the same orthogonal boundary coordinates as the squares in the above example, and these integrations can be factored into Nth powers, leading to the general result |
|
|
|
|
|
|
|
Now that we have P{A|B} we can use the conditional probability formula (4) to give |
|
|
|
|
|
|
|
Again we’ve made use of the fact that F(0) = 0. Knowing the value of P{A and B}, we can now use the other side of the conditional probability equation (4) to compute |
|
|
|
|
|
|
|
For a simple example, if each of the N components has an exponential failure distribution f(t) = λe–λt, we can insert the corresponding cumulative function F(t) = 1 – e–λt into this expression to give |
|
|
|
|
|
|
|
Just as we would expect, this result depends only on the length of the interval between t1 and t2, not on the absolute values of the times, because an exponential distribution has a constant failure rate, so the probability of failure during any specified length of time, given that the component is healthy at the beginning of that time interval, is independent of how long the component had been functioning previously. |
|
|
|
For slightly less trivial example, suppose each component has a Weibull failure distribution with parameters α and β. Inserting the corresponding cumulative function F(t) into the expression for P{B|A} we get |
|
|
|
|
|
|
|
Naturally if β = 1, the Weibull distribution reduces to an exponential distribution (with λ = 1/α), and the result depends only on the difference t2 – t1. However, with β ≠ 1, the result is not purely a function of the length of the interval, it also depends on the absolute values of t1 and t2. Setting t1 = (n–1)T and t2 = nT, we see that this expression for P{B|A} is identical to equation (3). |
|
|
|
Of course, we could also compute this directly as we did for P{A|B} above. For an arbitrary probability density function f(t), the value of P{B|A} is the ratio of the integrated joint density between t1 and t2, divided by the integrated joint density integrated over the range from t1 to infinity. The denominator represents the sample space restricted by condition A, meaning we exclude the possibility of failure of any component up to the time t1. Thus for the case N = 2 we have |
|
|
|
|
|
|
|
Again, this immediately generalizes to any value of N, i.e., we have |
|
|
|
|
|
|
|
which of course is identical to equation (2) raised to the Nth power, remembering that t2 = nT and t1 = (n–1)T. Inserting the cumulative probability distribution F(t) for the Weibull distribution, we get (again) the expression for the probability that all N components will fail on the nth mission, given that none have failed previously |
|
|
|
|
|
|
|
Incidentally, for fairly large values of n, we can make use of the first term of the binomial expansion |
|
|
|
|
|
|
|
to give the approximate relation |
|
|
|
|
|
|
|
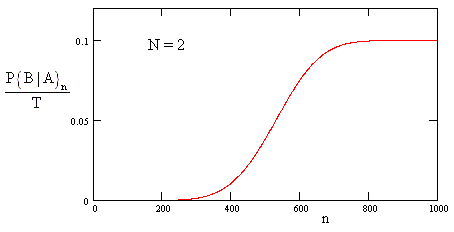
To illustrate the use of equation (5), consider a system consisting of N identical components, each with a Weibull failure distribution with parameters α = 2000 hours and β = 5. All N components are installed in new condition at time t = 0, which means the ages of the components are perfectly synchronized. (In practice, this would often not be the case. In fact, some systems specifically stagger the ages of redundant components, to avoid this kind of synchronization.) In some contexts the criterion of acceptable probability is expressed in terms of the probability of total failure per mission divided by the duration of a mission. We will call this the normalized probability. The normalized probability that all N components will fail on the nth mission (where each mission is of duration T = 10 hours), given that none have failed prior to that mission, is plotted below. |
|
|
|
|
|
|
|
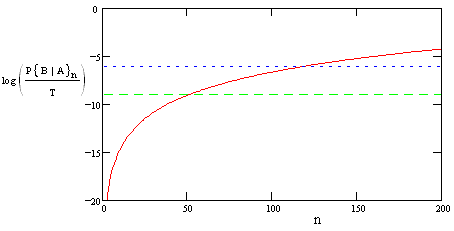
This shows that the conditional probability is quite low for about the first 200 missions, after which it begins to increase rapidly until reaching an asymptotic value of 1/T at around 700 missions. The asymptote represents a probability of 1, but we have normalized it by dividing by the mission time T = 10 hours. (The fact that the normalized probability is defined to be 0.1 for a mission having a virtual certainty of total failure is an anomaly arising from the use of “normalized probability” in some industries, since it is not a very well defined mathematical concept.) Ordinarily we are interested primarily in the system reliability in the region where the probability of total failure is quite low, so we will focus on the first 250 missions, and plot the logarithm of the normalized conditional probability, as shown below. |
|
|
|
|
|
|
|
This shows that the conditional probability of total failure is about 10–9 on the 50th mission, and is about 10–6 on the 120th mission. Depending on how much conditional risk we will tolerate, this formula enables us to determine the maximum “age” of a tolerable system. This assumes our tolerance is defined in terms of the conditional risk for each individual mission. If our tolerance was based on the average conditional risk, we would compute the average risk over the first k missions as |
|
|
|
|
|
|
|
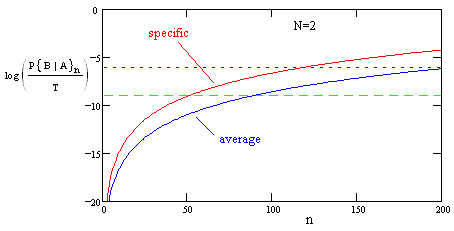
The figure below shows the logarithm of this average function superimposed on the previous plot. |
|
|
|
|
|
|
|
This shows that, if our requirement is that the average of the conditional probabilities be less than 10–9, we can allow about 88 missions, even though the 88th mission specifically has a conditional probability of about (0.8)10–7 of total failure. |
|
|
|
It’s worth emphasizing that the formulas derived above are based on the premise that all N components begin new at the same time t = 0, so the failure rates are synchronized, with the rates (typically) increasing as the components age. This means that although the components operate independently, their synchronized aging causes their failures to be statistically correlated, i.e., they are not statistically independent. Each component is somewhat more likely than average to failure during a mission when the other component fails. Neither of them is likely to fail during an early mission, and both are more likely to fail during a later mission, so there is a positive correlation between their failures. However, in practice, two or more components are often not synchronized, either because they are intentionally staggered, or because of random differences in when the individual units are installed and replaced. Notice that, if two (or more) aging components are out of phase, their failures can actually exhibit negative correlation, because the later missions of one component coincide with the early missions of the other component, and vice versa. In such circumstances it is highly unlikely that both would fail during a single mission – which of course is why redundant components are often intentionally staggered. Nevertheless, there are many circumstances in which synchronization is a reasonable assumption, such as in the delivery of completely new systems. |
|
|