|
Complete Markov Models and Reliability |
|
|
|
Given a system consisting of N independent components, each of which can be in one of two states (healthy or failed), the overall system can be in one of 2N states. Each state can be represented by an integer in the range from 0 to 2N – 1 such that the jth binary bit (from least to most significant) signifies the state of the jth component (with j ranging from 0 to N–1). For example, given a system with N = 8 components, the state in which the first, second, and sixth components are failed would be represented by the decimal number 35, whose binary representation is 00100011. For any integer m, let mj denote the coefficient of 2j in the binary representation of m. In other words, mj is the jth binary bit of m. Bit-wise logical operations can be performed on integers, such as a = b AND c, which signifies that aj = bj AND cj for all j. |
|
|
|
If λj is the failure rate (assumed constant) of the jth component, and if we let Pk denote the probability of the system state represented by the integer k, then the complete Markov model for the system failures consists of the equations |
|
|
|
|
|
|
|
Thus each state is involved in n failure transitions, which represent flow either into or out of the state, depending on the states of the components. If the jth component is healthy in state m, then mj = 0, and the summand on the right side reduces to –λjPm, signifying the flow from state m into state m + 2j. On the other hand, if the jth component is failed in state m, then mj = 1, and the summand is λjPq where q = m 2j, signifying the flow into state m from state m – 2j. |
|
|
|
Since every transition represents flow from one state into another, we can implement all the flows simply by distributing from the appropriate emitting states all the flow into each state, or, alternatively, by distributing to the appropriate receiving states all the flow out of each state. The latter turns out to be more suitable for numerical purposes when combined with repair transitions, which can be represented either by discrete re-distribution of state probabilities at scheduled intervals, or by continuous flows at rates with the same mean transition times. |
|
|
|
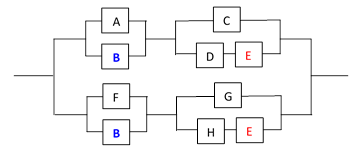
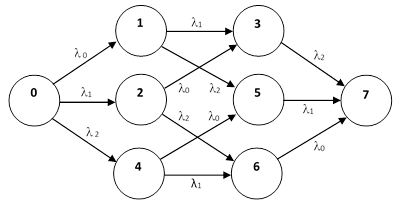
To illustrate the application of this analysis method, consider the 8-component system shown below (an example suggested by Prescott and Andrews). |
|
|
|
|
|
|
|
Each component will be regarded as an individually replaceable unit. The Boolean expression for complete system failure is |
|
|
|
|
|
|
|
The latter expression consists of mutually exclusive terms, so the probabilities of the four terms are strictly additive. Therefore, we can use it to directly compute the probability of total system failure given the probabilities of the individual components being failed. We are given the failure rates of the individual components A through H as (respectively) 50, 35, 75, 60, 40, 50, 75, and 60 failures per million hours. For any specific state we can compute the probability of total system failure during a 10-hour period (for example), assuming the system started in the specified state. Beginning from the “full-up” state, the probability normalized to a per-hour basis is 3.13E-11. However, if one of the eight basic components is failed at dispatch, the probabilities of total system failure during a 10-hour mission, normalized to a per-million-hour basis, are as listed below. |
|
|
|
|
|
|
|
These rates are all fairly small, so in practice we would typically not need to inspect the individual components very often. We would classify these failures as “long-time dispatch” items. In fact, the conditional failure rates with components D or H failed at dispatch are so low that we might not require any inspection of those components at all. |
|
|
|
If we examine the conditional system failure rates (i.e., probabilities of failure during a 10-hour mission, normalized to a per-million-hour basis) when dispatching with two or more components failed, we find, not surprisingly, that the combinations with the largest conditional system failure rates consist of those that are just one component failure away from system failure. The conditional system failure rates in these cases are obviously virtually equal to the failure rate of that one component. The minimal combinations of this type giving a system failure rate less than 100 per million hours are listed below. |
|
|
|
|
|
|
|
There are also combinations that give conditional system failure rates greater than 100 per million hours. These are cases when the failure of any one of a set of two or more component failures results in total system failure, so in these cases the conditional system failure rates are essentially sums of two or more of the individual components failure rates. The minimal combinations in this category are listed below. |
|
|
|
|
|
|
|
Ideally the system inspection and repair rates would be tailored to the conditional system failure rates. This not only makes sense from a system-design standpoint, it also tends to simplify the analysis of the system reliability, because the repair transitions are aligned with the failure transitions, and it’s often possible to consolidate the 2N states into a small number of aggregate states. However, in some circumstances, the inspection and repair rates are governed by other considerations. For example, there may be no practical way of inspecting some of the components while the system is in service. Therefore, a fully general analysis method must be capable of accommodating arbitrary repair transitions. |
|
|
|
Suppose for the system described above we define the inspection and repair intervals listed below. |
|
|
|
1600 hours: A, B, F |
|
200 hours: CD, CE, GH, EG |
|
10 hours: AGH, AEG, BCD, BCE, BGH, BEG, CDF, CEF |
|
|
|
Any given state can readily be checked to determine in which (if any) of the categories it resides by a simple test. Letting k denote the integer representing the state, and letting m denote the integer corresponding to one of the above combinations, the state k qualifies for the category of m if and only if (k AND m) = m. Of course, each state is placed in the highest category for which it qualifies. Of the 256 distinct states in the 8-component system described above, we find that 13 are dispatchable forever (i.e., they are not in any of the prescribed inspection/repair categories), 78 are in the “long time” (1600 hour) category, 28 are in the “short time” (200 hour) category, 56 are in the “no dispatch” (10 hour) category, and 81 are complete system failures. |
|
|
|
We make the further stipulation that the 1600-hr conditions are repaired only to the extent of making them dispatchable. For example, if the system state is AC at the time of a 1600-hr check, then only component A will be repaired, because a failed C component (by itself) does not ever have to be repaired. We could similarly assume only the minimum repairs for the 200-hour and 10-hour states, but in those cases it is more problematic, because (for example) the state CD could be rendered fully dispatchable simply by fixing either C or D, but there is no particular reason to fix one and leave the other failed. (This is especially true for strictly periodic inspections and repairs, because in that case we don’t know, upon finding C and D both failed at a certain inspection, which of them failed first.) Therefore, we will assume these states are fully repaired, i.e., the repair transitions from these states return the system to the no-failure state. |
|
|
|
Clearly the inspection/repair intervals specified above are not perfectly aligned with the conditional failure probabilities. For example, there is no evident reason for imposing an interval of 1600 hours on components A,B,F while having no interval at all for components C,E,G, since the latter actually give a greater conditional system failure rate. Likewise one would normally include CG in the 1600-hour category, because it’s conditional rate is actually greater than the conditional rate for AF. More seriously, if we regard states with conditional probabilities greater than 100 per million hours as “non-dispatchable” (i.e., the 10-hour category), there are several states that ought to be non-dispatchable but that are allowed to dispatch under the intervals specified above. For example, the state ABE gives a conditional system failure rate of 125 per million, and yet it is only in the 1600-hour category. |
|
|
|
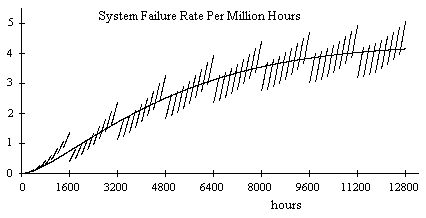
Despite these concerns, it’s interesting to consider a general analysis method that can correctly analyze the system, even given a set of repair transitions that are somewhat arbitrary and not well aligned with the failure transitions. A BASIC program to perform a straight-forward numerical integration of the system equations (1) along with the defined repair transitions is shown in Attachment 1. This program computes the system failure rate as a function of time, and shows that the asymptotic behavior is a nested saw-tooth that ranges from 3.25E-06 to 5.25E-06 per hour. A plot of the rate as a function of time for the first 12800 hours of operation is shown below. |
|
|
|
|
|
|
|
The failure rate function has a minor period of 200 hours and a major period of 1600 hours. We can also model the repair transitions continuously, using a rate of 2/T for an inspection interval of T hours. (We use 2/T instead of 1/T in order to match the mean time between failure and repair for periodic inspections. If we were modeling “MEL” repairs with a dispatch allowance of T hours we would use 1/T.) The program in Attachment 1 can be converted to continuous repairs simply by replacing the discrete re-distributions every T hours with continuous flows at the indicated rates. This gives the continuous curve shown on the figure above. |
|
|
|
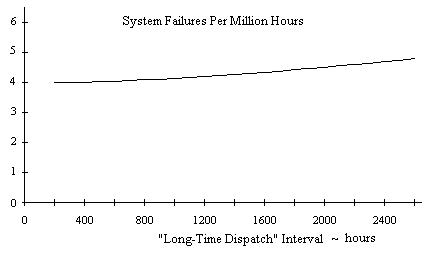
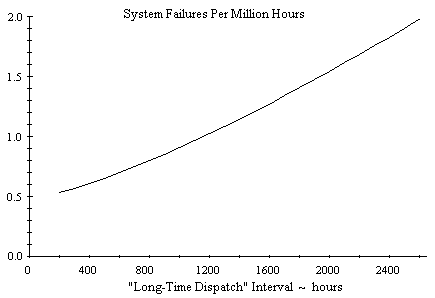
The preceding discussion was based on a “long-time dispatch” interval of 1600 hours, but we can determine the asymptotic system failure rate for a range of intervals, possibly for the purpose of selecting an interval that gives some desired failure rate. The figure below shows the system’s asymptotic failure rate for “long-time dispatch” intervals ranging from 200 to 2600 hours. |
|
|
|
|
|
|
|
It’s worth noting that we have plotted the average asymptotic failure rate, whereas the failure rate actually oscillates in a nested limit cycle as shown in the previous plot. To be conservative, we might choose to characterize the failure rate by a curve along the upper part of the limit cycle’s envelope. This would ensure that we account for the predicted failure rate on each individual flight, regardless of where that flight happens to occur in the maintenance cycle. For the present example it makes very little difference, but the magnitude of the limit cycle oscillation on other systems can be much greater, so the difference between the long-term average and the worst single-flight failure rate can be significant. |
|
|
|
We also note that the system failure rate in this example is fairly insensitive to the long-time dispatch interval. Furthermore, rather than approaching zero as the interval goes to zero, the system failure rate approaches a rate of 4 failures per million hours. This is because the condition CG is not in any of the inspection/repair categories, so the system can operate indefinitely in that state. As a result, we find that the system spends nearly 10% of the time in that state, from which only a single failure (of component E) will lead to system failure. Hence, regardless of how short we make the inspection and repair intervals, the system failure rate can never be less than 10% of the failure rate of component E. This is why the dispatch intervals (both long-time and short-time) have only a second-order effect on the system failure rate. With no inspection/repair on the CG state, the bulk of the system failures occur from this state, which is unaffected by the lengths of the intervals. |
|
|
|
To remedy this, we can simply include the condition CG in the “long-time dispatch” category, yielding a much more reliable system, with an overall failure rate that varies as a function of the dispatch interval as shown in the figure below. |
|
|
|
|
|
|
|
Not only does this give a substantially lower system failure rate, it is a more sensitive function (in proportion to the overall magnitude) of the long-time dispatch interval, so it would make sense to infer a suitable inspection/repair interval from this plot. The curve shown on this plot is for a short-time interval of 200 hours. If we lower that interval, we lower the entire curve, and as the short-time interval goes to zero the above curve essentially intersects with the origin, i.e., the system failure rate drops to virtually zero if we make both inspection/repair intervals zero. As noted previously, if we inspect and repair every component before each dispatch (on a 10-hour mission), the system failure rate is 0.000313 per million hours. This illustrates one way of verifying adequate maintenance coverage and the absence of latent faults. |
|
|
|
Regarding the feasibility of applying the complete Markov analysis to arbitrary systems, we note that since the number of states for a system of N components is 2N, this method would be impractical for values of N greater than about 16, whereas real system can have hundreds or thousands of individual components. However, in most cases those individual components can be aggregated into a much smaller number of meta-components, and the Markov model can operate at the level of these meta-components. For example, in the system describe above, each of the 8 “components” A though H may actually consist of a large number of sub-components, but all the sub-components of a given component are simply treated as contributors to the failure rate of the component, and the sub-components are not individually repairable, so nothing is lost by analyzing the system on the “LRU” (line replaceable unit) level. In practice, very few critical systems involve more than a dozen separate LRUs (and most involve far fewer). |
|
|
|
Of course, in theory, we can easily imagine systems with a large number of LRUs, arranged and maintained in such a way that they cannot be consolidated into aggregate states without sacrificing fidelity of the model. This is why no completely general analysis method can guarantee that it can achieve any specified level of precision in less than exponential running time. The general problem of evaluating Boolean expressions is known to be “NP-complete”, meaning there does not exist a sub-exponential algorithm for the general case. (If such an algorithm did exist, it would jeopardize all known high-security encryption schemes.) |
|
|
|
Sometimes Monte Carlo methods are applied to such problems. A brute-force approach would be to simulate the system in the time domain, introducing faults and repairs in accord with the prescribed failure distributions and maintenance strategies. A more efficient technique is to generate the times of the failures of each component by selecting inter-failure intervals from the appropriate distributions. In effect, for a system with N components, each of which fails roughly k times during the life of the system, this amounts to randomly choosing points in a kN-dimensional space, and evaluating the number of total system failures for each “point”. However, a great deal of care must be taken to ensure that the “randomly” selected intervals for the components are truly independent. This is more problematic than it sounds, because computers aren’t capable of generating truly random numbers, they can only generate pseudo-random numbers, and every method of generating pseudo-random numbers gives non-random correlations of some kind. As Knuth said in “The Art of Computer Programming” |
|
|
|
Every random number generator fails in at least one application… The most prudent policy for a person to follow is to run each Monte Carlo program at least twice using quite different sources of random numbers before taking the answers of the program seriously… |
|
|
|
This is especially true when the object of the program is to compute the probabilities of extremely improbable events that may involve the intersections of multiple random component failures. This is precisely the kind of situation that is most likely to manifest the non-random correlations in pseudo-random numbers used by a Monte Carlo program. In order to validate that the pseudo-random number generator has acceptable properties for any given application, it must be tested, and for this purpose some other (non Monte Carlo) method of determining the correct result is needed, unless we are content to rely on a comparison of multiple “quite different” pseudo-random sources. It’s been said (only half in jest) that more computer time has been spent testing pseudo-random numbers for subtle statistical flaws than has been spent using them in applications. |
|
|
|
Of course, the utility of Monte Carlo methods is that they relieve us of the need to devise a deterministic search pattern, which may be appealing in cases when the state space to be searched is very complex. However, the essential difficulty of evaluating reliability for arbitrary systems is not primarily due to the complexity of the state space boundary, it is due to the resolution that may be required. The Monte Carlo method does nothing to enhance the resolution or efficiency of the search. To illustrate, suppose there are 100 million identical boxes, one of which contains a valuable prize. To find the prize we can either follow a deterministic search pattern, checking each box in turn, or we can randomly select boxes to check. If we take the deterministic approach, we will never check any box twice, so this is the most efficient possible method. However, the boxes may be arranged in a very complicated way, and there are many different choices for how to step through all the boxes, so we will need to carefully plan how we are going to proceed. We may choose a search pattern that exhaustively covers each small area before going on to the next. In contrast, a Monte Carlo approach doesn’t require such systematic planning, and it will typically reach locations over a larger region of the state space in less time (because the random choices are scattered over the entire space), but at much lower resolution. Also, duplications are possible, because nothing prevents our random process from selecting a given box more than once. Consequently, the worst case time required to find the prize is actually longer for the Monte Carlo approach (because of duplication) than for a well-defined deterministic algorithm. |
|
|
|
Needless to say, if we happen to know that there are actually several prizes, distributed in a cluster of boxes in a single region, then the optimum search algorithm would work at a more coarse level of resolution, but on whatever is the appropriate level, the relative merits of random and deterministic search algorithms remain the same. The difficulty of defining a general method, guaranteed to work for arbitrary systems, is due to the fact that we do not know, a priori, the level of resolution, so any method that assumes anything other than the fully exponential resolution can be invalidated. |
|
|
|
Even without the complications arising from repair transitions, the simple evaluation of monotone Boolean functions is NP-complete, so even straight-forward fault trees are, in the general case, computationally intractable. However, there do exist algorithms that can place rigorous upper (and lower) bounds on the probability of monotone Boolean expressions, and in virtually all practical cases this upper bound is robust (i.e., will run in polynomial time), even when applied to systems with over 1000 components and hundreds of “multiply occurring events” in the Boolean expressions. This is the best possible result, because it automatically guarantees rigorous accuracy of the results, and focuses the computational effort on improving the precision of the results, which, in virtually all practical cases, can be brought within desired bounds in polynomial time, exploiting the empirical fact that Boolean expressions arising in practical applications (suitably reduced) are hardly ever computationally intractable. |
|
|
|
Returning to the use of complete Markov models to evaluate the reliability of a system consisting of N basic components, it’s worth noting that, using continuous repairs, the steady-state result can be computed algebraically in a very straight-forward way. Consider the complete 3-component system shown below. |
|
|
|
|
|
|
|
Each state j also has a repair transition μj (not shown) with an assigned rate, sending the system back to some less-failed state. If all repairs are complete (meaning that the system is returned to the state 000), the steady-state system equations are |
|
|
|
|
|
|
|
This is a particularly simple case (with all repair transitions returning to the no-fault state), because the state probabilities can be computed recursively, beginning with the one-failure events, then the two-failure events, and so on. Letting cj = Pj/P0, we have c0 = 1, and the single-fault equations give |
|
|
|
|
|
|
|
Then the double-fault equations give |
|
|
|
|
|
|
|
and finally the triple-fault equation gives |
|
|
|
|
|
|
|
Since the sum of the probabilities of all the states must equal 1, we can now compute |
|
|
|
|
|
|
|
and with this together with the cj values we can compute the probability Pj = cjP0 of each state. The pattern in these formulas is clear, and it can easily be extended to include partial repairs. In general, the steady-state equation for the nth state is |
|
|
|
|
|
|
|
where “j → n” signifies the states j whose repair transitions lead to state n. Solving this for Pn gives |
|
|
|
|
|
|
|
The presence of the “j → n” terms means that these equations cannot be solved recursively in a single step. We could, of course, simply invert the 2N x 2N transition matrix to solve for the probabilities, but in practice it may not be feasible to invert such a large matrix. A much more efficient approach is to iterate the system equations in a manner similar to solving potential flow fields in computational fluid dynamics, where the Laplace equation is applied to each node of a grid with specified boundary conditions. To facilitate this, notice that the system equations are invariant under re-scaling of the P values, so only the ratios of the P values are significant. Thus we can divide through by P0 (which is certainly non-zero) to give the equivalent equations |
|
|
|
|
|
|
|
The advantage of this system of equations is that it has a fixed boundary condition, c0 = 1, so we can easily apply the system equations iteratively to the other states until the results converge, which typically occurs in just a small number of iterations because of the hierarchical nature of the state probabilities. (For a discussion of this iteration method, and its relation to the well-known Gauss-Seidel method, see the note on Iterative Solutions of Homogeneous Linear Systems.) Once the ratios cj have been determined, the total system failure rate is given by |
|
|
|
|
|
|
|
where “F” denotes the set of total system failure states, and μF is the repair (or replacement) rate for these states. Notice that the ratio of cj summations equals the ratio of the number of totally failed systems divided by the number of unfailed systems, which is inversely proportional to μF. This shows that the value of μF has no effect on the result, which is as we would expect, since λsys represents the failure rate of the population of operational systems. The totally-failed systems are not in this population, so λsys is independent of how long we take to repair or replace totally-failed systems. |
|
|
|
A simple implementation of this method is shown in Attachment 2. In this program we have also implemented a “minimal repair” strategy, according to which only the components in any mincut of the governing repair category are repaired. This purely algebraic method is vastly more efficient at computing the long-term average failure rate than either the full time-dependent solution method or the Monte Carlo method. Another desirable feature of the steady-state algebraic approach is that the validity of the results does not depend on dubious auto-correlation properties of pseudo-random number sequences. |
|
|
|
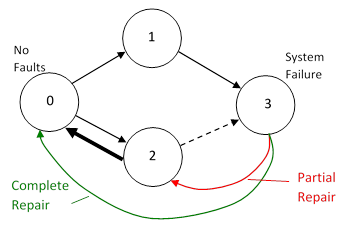
Incidentally, the original example discussed above (with no inspection of fault condition CG) exhibits an interesting dependence on the choice of repair strategies. We might choose to repair all present faults whenever any repairs take place (so every repair transition would take the system to State 0), or we might apply the minimal repair strategy to just the “long-time” faults, or to just the long-time and short-time faults, or to the long-time, short-time, and no-dispatch faults, or to all fault conditions (including total system failure). For the original example, the results of these different repair strategies are 2.5611, 4.3424, 4.5679, 4.5762, and 4.5744 failures per million hours respectively. Notice that applying the minimal repair strategy to the system failure states, rather than performing complete repair of those states, actually results in a (very slight) reduction in the overall system failure rate. This may seem counter-intuitive, and it is certainly atypical, but such behavior is possible when the repair categories are inequitable (as they are in the original example). In essence the situation is as illustrated below. |
|
|
|
|
|
|
|
If all failed systems are fully repaired to the No-Fault state, they have a certain mean time to arrive back at the System Failure state, which is almost always by way of State 1 in this example, because there is no repair on State 1, whereas there is a repair on State 2. However, if all failed systems are just partially repaired, some will be sent back to State 2, where they will most likely be repaired back to State 0 after a short time, and from State 0 they will then return to State 3 by way of State 1. Thus the mean time from State 0 to State 3 is (slightly) less than the mean time from State 2 to State 3. As a result, the overall system failure rate is actually reduced (slightly) by applying partial rather than complete repairs to the failed systems. This peculiar behavior disappears if we place the CG condition (corresponding to State 1 in the simplified drawing above) into the long-time dispatch category. |
|
|
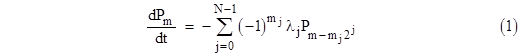
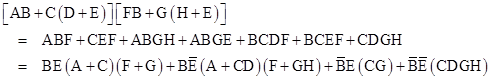
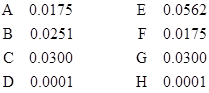
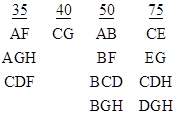
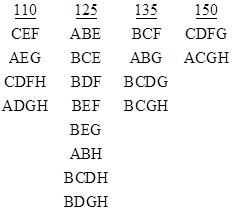
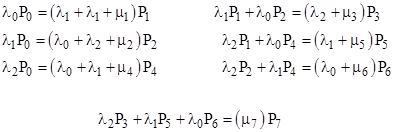
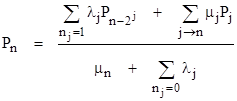
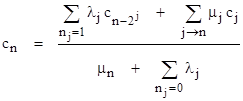
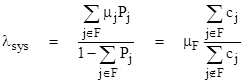
{kind=link}
{kind=link}