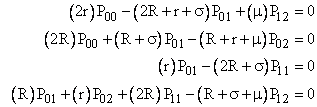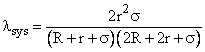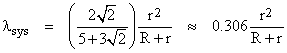|
Markov Modeling for Reliability – Part 4: Examples |
|
|
|
4.1 Primary/Backup System with Internal/External Fault Monitoring |
|
|
|
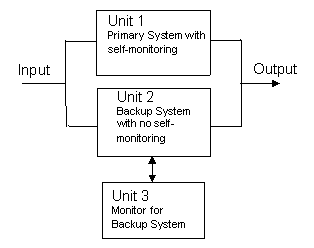
The system shown schematically in the figure below consists of a primary unit (Unit 1) with continuous internal fault monitoring, a backup unit (Unit 2) with no self-monitoring, and an external monitoring unit (Unit 3) whose function is to monitor the health of the backup unit. |
|
|
|
|
|
Diagram of Active System with self-monitoring and |
|
Back-up System with an Independent Monitor |
|
|
|
The failure rate of Unit 1 is l1 = 5.0E-05 per hour. The full time self-monitoring of this unit enables it’s functionality to be verified prior to every flight. (The duration of each flight is assumed to be 5 hours.) If found to be faulty or inoperative, it is repaired before dispatch. |
|
|
|
The failure rate of Unit 2 is l2 = 2.5E-05 per hour. The backup system has no self-monitoring, but is monitored continuously by an independent monitor (Unit 3). If the backup system fails and the monitor is working, the backup is repaired before the next dispatch. If the monitor is not working, the backup can fail latently, but it is checked every 10 flights (50 hours). If the backup unit is found faulty at one of these 50-hour checks, with no indication of backup system failure from the monitor, it is assumed that the monitor system is also failed, so both Units 2 and 3 are repaired prior to the next flight. |
|
|
|
The external monitor (Unit 3) has a failure rate of l3 = 2.5E-05 per hour. If it fails, it can be repaired in one of two ways. First, as noted above, if the backup system is found failed at its periodic 50-hour inspection and there was no monitor indication of a backup system failure, then the monitor is repaired along with the backup system prior to the next flight. Second, a periodic check of the monitor is performed every 100 flights (500 hours), and if the monitor is found to be failed, it is repaired prior to the next flight. |
|
|
|
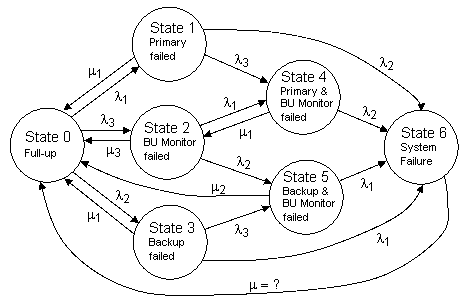
The MTBFs of the individual units are 20,000 and 40,000 hours, whereas the periodic inspection intervals are only 5, 50, and 500 hours, all of which are orders of magnitude smaller than the MTBFs. Also, most of the states being repaired are first-order states, i.e., they are just one failure removed from the full-up state, so there is no appreciable loss of accuracy in modeling these repairs as continuous transitions with constant rates given by m = 2/T for the respective intervals. The exception to this is the state in which both the monitor and the backup system are failed. The 50-hour periodic inspection/repair of this state will actually have an effective repair rate somewhat greater than 2/T, but it is conservative to use 2/T, so for convenience we will use this expression for all the repair rates. Thus we set m1 = 2/5, m2 = 2/50, and m3 = 2/500, and we can construct the Markov model for the overall system as shown below. |
|
|
|
|
|
|
|
As usual, we set the repair rate on the total system failure state (State 6) to infinity, which effectively eliminates that state from the system equations. The system failure rate is simply the rate of entry into that state, i.e., lsys = (P1 + P4)l2 + (P3 + P5)l1. Also, since the probabilities of the remaining states must sum to 1, we can disregard one of them, so we need only consider the steady-state equations for the states 1 through 5, as listed below. |
|
|
|
|
|
|
|
Combining these with the conservation equation P0 + P1 + P2 + P3 + P4 + P5 = 1, we have six equations in six unknowns. In terms of the matrix notation of Section 2.3, the average system failure rate for this example is |
|
|
|
|
|
where |
|
|
|
|
|
and L is the row vector L = [ 0 l2 0 l1 l2 l1 ]. Inserting the values of the failure and repair rates, this gives the result lsys = 6.42E-09 per hour. |
|
|
|
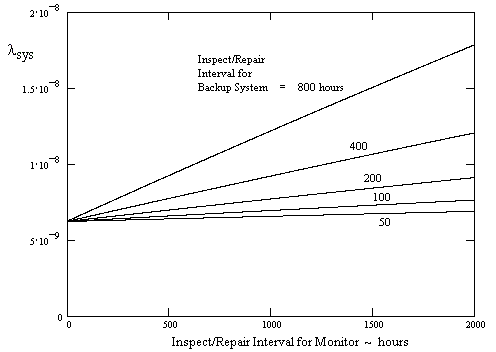
The sensitivity of the system failure rate to variations in the component failure rates and repair times can also be evaluated. For example, the plot below shows the system failure rate as a function of the monitor inspection interval for various values of the backup system interval. This type of plot can assist the analyst and designer in determining the optimum maintenance intervals the achieve the required level of reliability with the minimum economic burden. |
|
|
|
|
|
|
|
|
|
|
|
4.2 Two-Unit System with Latent Failures of Protective Elements |
|
|
|
Consider a system consisting of two redundant units, each equipped with protection from a common threat (such as lightning, inclement weather, etc), and suppose failure of the protection occurs at the rate r and is undetectable until the unit is subjected to the external threat, at which time the unit fails. In addition, each unit has a detectable failure rate due to generic causes of R, and an exponential repair transition with rate m. Whenever a unit is repaired, its threat protection is also checked and, if necessary, repaired. Let s denote the rate of occurrence of the common external threat. |
|
|
|
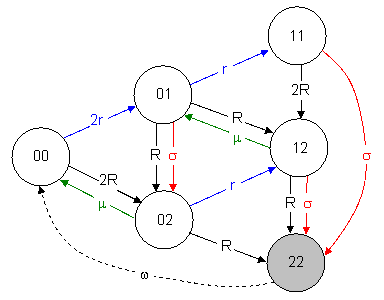
Each unit can be in one of three states, which we will denote as 0, 1, and 2, corresponding to fully healthy, protection failed, and fully failed, respectively. (For a fully failed unit it is irrelevant whether the protection is failed or not, because the unit will remain inoperative until it is repaired, at which time the protection will also be restored if it is failed.) Since the two channels are symmetrical, the overall system can be in one of just five functional states, denoted as 00, 01, 02, 11, and 12. (The state 22 signifies the non-functional state with both units inoperative, which will be repaired immediately.) The Markov model for this system is shown below. |
|
|
|
|
|
|
|
As discussed previously, the total failure state (“22”) is just a place-holder, since a system leaves the population when it enters this state, and doesn’t return to the population until it is repaired or replaced by a system in state 00. Therefore, the rate w is irrelevant to the hazard rate of the operational population. The system failure rate is the rate of entering state 22, which is |
|
|
|
|
|
|
|
The steady-state system equations are |
|
|
|
|
|
|
|
along with the conservation equation |
|
|
|
|
|
|
|
This gives us five equations in five unknowns, and we can solve this system of equations to determine the steady-state values of P02, P11, and P12, which we can substitute into equation (4.2-1) to give the system failure rate explicitly as a function of R, r, m and s. |
|
|
|
The plot below shows the rates of the four ways of entering state 22 as a function of s, given the parameters R = 10-5, r = (0.02)R, and m = 1/150. The upper line represents the rate of entering state 22 from state 02, which is by far the most likely way of reaching state 22. The red lines represent the rates triggered by the occurrence of the external threat and, as can be seen, the maximum contribution occurs for s near the square root of 2 times R + r. |
|
|
|
|
|
|
|
Now, at the two extremes of s equals zero or infinity, the system failure rate is |
|
|
|
|
|
|
|
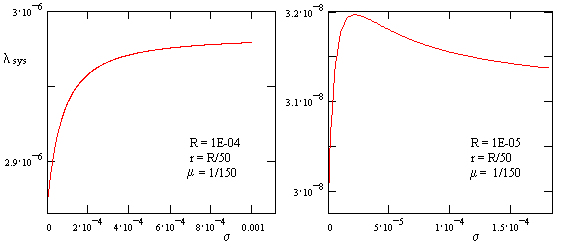
These two expressions are identical, except that R is replaced with R + r. Depending on the values of the parameters, the system failure rate may increase monotonically between these two levels, or it may pass through a maximum and drop back down, as illustrated in the two plots below. |
|
|
|
|
|
|
|
In many applications the value of s (the rate of encountering the external threat of sufficient severity to cause a unit failure) is unknown, so it is necessary to choose a conservative value. If we set m to infinity (meaning that individual detected unit failures are assumed to be repaired immediately), the expression for the system failure rate reduces to |
|
|
|
|
|
|
|
which is zero if s is either zero or infinite. In this case we can differentiate with respect to s and set the resulting expression equal to zero to find that the value of s giving the maximum value of lsys is |
|
|
|
|
|
|
|
so the worst-case system failure rate (assuming immediate repair of detected component failures) is |
|
|
|
|
|
|
|
This shows that complete system failure for the two-unit system is on the order of the failure rate of a single unit. In fact, for a system with zero rate of detected failures (R = 0), and with a rate r for failure of each individual unit’s protection feature, the worst-case system failure rate is (0.306) r. |
|
|
|
|
|
4.3 Three-Unit System with Latent Failures of Protective Elements |
|
|
|
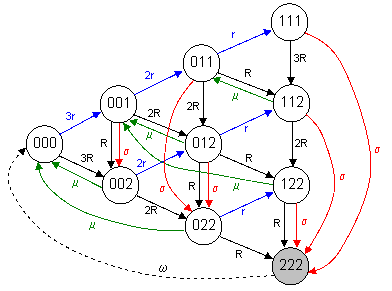
We can apply this same type of analysis to a 3-unit system, where each units can be either healthy, or with undetected failure of protection, or in a detected failure state. As before, we denote these by the indices 0, 1, and 2. The units are symmetrical, so the order doesn’t matter. Thus the subscript “012” (for example) signifies that one unit is fully healthy, one has failed protection, and one is in a detected inoperative state. The Markov model for this system is shown below. |
|
|
|
|
|
|
|
As explained for the 2-unit system, the total failure state (222) is just a place-holder, so there are only nine states of the system. For convenience we will number the states from 1 to 9 in the order 000, 001, 002, 011, 012, 022, 111, 112, 122. By examining the model we can define the transition matrix M shown below. |
|
|
|
|
|
|
|
In terms of this matrix the system equations are |
|
|
|
|
|
|
|
where P is the column vector consisting of the probabilities of states 1 through 9. The eventual steady-state solution has dP/dt = 0 and therefore MP = 0, but since the rows of M sum to zero they are not independent. Replacing the first row of M with the condition that the sum of all the probabilities is unity, we have nine independent conditions, so we can solve for the probabilities. Letting A denote the modified version of M (i.e., with the first row replaced with 1’s), and letting C denote the column vector with C1 = 1 and Cj = 0 for all j > 1, the steady state probabilities are given by |
|
|
|
|
|
|
|
In terms of these probabilities, the total system failure rate can be read off the model diagram as |
|
|
|
|
|
|
|
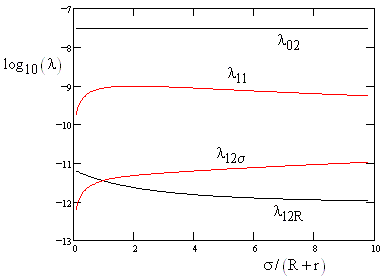
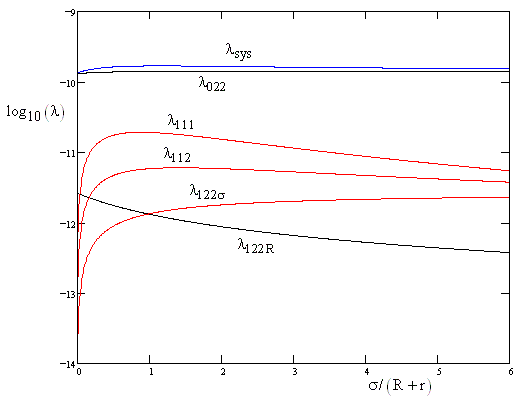
where we have reverted back to the original index notation for the various states. To illustrate, consider the case of a system comprised of three parallel units, each with a detected failure rate R = 10-5 per hour and undetected rate r = R/50 (i.e., 2%) of protection failure, and a repair rate m = 1/150 hours. The five individual contributions to the overall system failure rate, along with the total rate, are plotted in the figure below (on a logarithmic scale). |
|
|
|
|
|
|
|
This example (as well as the previous two-unit example) involves two somewhat unusual features. First, the system relies on the failures of certain components to drive the inspection and repair of other components which are themselves latent. Great care must be taken when invoking this sort of argument, because the average rate R of detected failures may not be uniformly applicable to all the systems in service. For example, it may be that half of the in-service units each fail (detected) twice per year, whereas the other half of the in-service units essentially never fail, i.e., they have R = 0. The average failure rate for the entire fleet of units is one failure per year, and yet half the fleet will operate for many years without a failure. As a result, it would be misleadingly optimistic to claim credit for a once-per-year inspection of the latent protection components for those units. |
|
|
|
The second unusual feature of this example is both more subtle and more robust. It accounts for the fact that latent failures of protection components will be revealed at the rate of external disturbances severe enough to cause (in the absence of protection) loss of function. This is why, in example 4.2, the rate of total system failure remains on the order of r, even if we assume R = 0. In other words, even if no credit is taken for inspections of the protection components triggered by detected failures, it is still not necessary to assume that all the protection features are latently failed, because failures of those features in an individual unit will be disclosed at a rate proportional to the threat. |
|
|