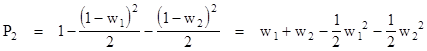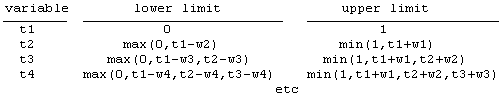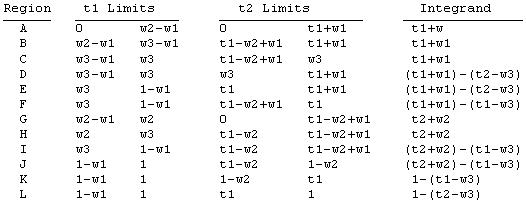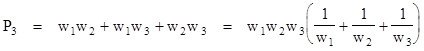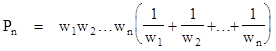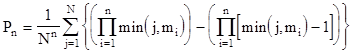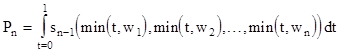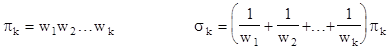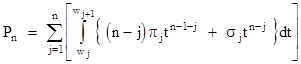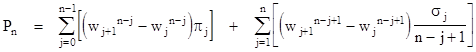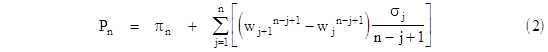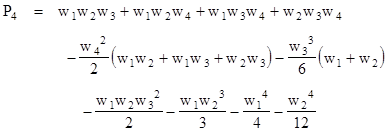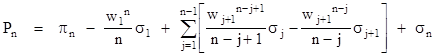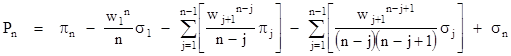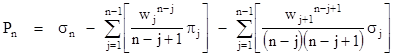|
Meeting Probabilities |
|
|
|
Given n independent random variables, each evenly distributed over the interval 0 to 1, the probability that all n are within q of each other (for any q < 1) is |
|
|
|
|
|
|
|
This can be derived in several different ways. For example, we can divide the unit interval into k equal segments, and note that the probability of n randomly selected points all falling within j consecutive segments corresponds approximately to the probability that all n points fall within q = (j/k) of each other. This correspondence becomes exact in the limit as k goes to infinity (holding q constant). Equation (1) can also be derived from a geometrical point of view. Given a unit "cube" in n dimensions, equation (1) represents the fraction of the cube's content ("volume") consisting of points with orthogonal coordinates [x1, x2, ..., xn] such that |xi – xj| < q for all i,j. (See The Shape of Coincidence for more on the geometrical aspects of this equation, and its relation to the rhombic dodecahedron.) |
|
|
|
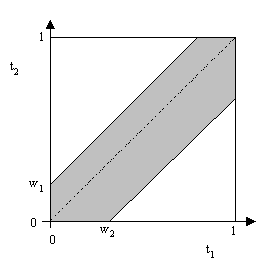
One possible generalization of this is to allow different tolerances on the different events. For example, suppose each of n people are to arrive at a certain location at some randomly chosen time between 1:00 PM and 2:00 PM, and each person will wait a certain amount of time before leaving. Say, for example, with n = 2 people, one can wait for w1 and the other can wait for w2 (both expressed as fractions of the total time interval). What is the probability that they will meet? Geometrically it's easy to see that this is just given by the are of the shaded region in the unit square shown below: |
|
|
|
The shaded area equals to total square area minus the two excluded triangles, so we have |
|
|
|
|
|
|
|
More generally, for n people with waiting times w1, w2, .. , wn, we just need to evaluate the integral of 1 over the following ranges of the arrival times t1, t2, .., tn: |
|
|
|
|
|
|
|
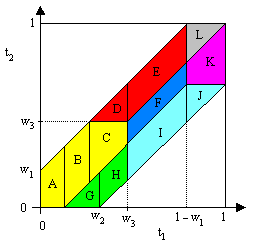
Obviously this becomes extremely complicated as n increases. To illustrate, consider the case n = 3. We need to divide the problem into 12 separate double integrals over t1 and t2 in order to specify fixed integration limits for each one. Letting w1 denote the smallest waiting time, and w3 the largest, these 12 regions are illustrated below as the regions denoted by A through L. |
|
|
|
|
|
Within each of these regions we need to integrate the difference between the high and low integration limits for t3. The integration limits and integrands are listed below |
|
|
|
|
|
|
|
Evaluating all twelve of these integrals and simplifying gives the result |
|
|
|
|
|
|
|
For example, with 3 people who can wait w1 = 1/4, w2 = 1/3, and w3 = 1/2 (15 minutes, 20 minutes, and 30 minutes, respectively) the probability of all three of them being at the location simultaneously during the hour is exactly 1435/5184, which is about 0.27681. |
|
|
|
Naturally both the formulas for n = 2 and n = 3 reduce to equation (1) when all the waiting times are equal. It's also worth noting that the formula for n = 3 is not symmetrical in the three waiting times, because the boundaries of the 3-dimensional solid representing the meeting region in phase space depend on a set of min and max selections, so the result depends on the ordering of the parameters, with w1 the smallest and w3 the longest waiting time. |
|
|
|
As n increases the direct integration method for arbitrary and unequal waiting times rapidly becomes much more complicated, because the waiting times must be truncated whenever someone arrives with less than his waiting time remaining before the end of the interval, and a similar truncation occurs at the beginning of the hour. Geometrically, we're dealing with the volume of an extremely complex n-dimensional asymmetrical polyhedron whose volume can't generally be given by a simple formula, except in the highly symmetrical case when all the d values are equal, or when n is very small (like the cases of n = 2 and n = 3 given above). |
|
|
|
To derive a more efficient method of determining the probabilities for larger values of n, we may begin by considering a similar questions whose answers can immediately be given by fairly simple formulas with arbitrary n. Suppose we eliminate the boundary truncation in the original problem by wrapping the 1-hour interval around in a circle of unit circumference, and stipulating that the jth person is present for a continuous span of exactly wj on that interval, and the location of each wj is uniformly and independently distributed around the circle. Now we can ask for the probability that n spans of length w1, w2, ...,wn will have some common overlap. Let's also assume that the d values are all fairly small relative to the entire interval, so that w1 + w2 + ... + wn is less than 1. (This allows us to avoid complications due to wrap-around.) |
|
|
|
Consider first the discrete case, i.e., suppose the circumference of the circle is divided into N equal increments, and the n randomly placed spans have discrete lengths of m1, m2, .., mn increments respectively. The total number of possible arrangements of the spans is Nn, so we need to determine how many of those contain at least one increment of overlap between all the spans. Obviously each configuration with overlap can be translated into N different positions, so we really just need to find the number of distinct intrinsic overlap configurations of these n spans. If we fix one particular increment on the circle and require that all the spans contain that increment, then the number of arrangements that satisfy this requirement is obviously the product m1m2 ...mn. However, this counts the intrinsic arrangements with two increments of overlap twice, because of translation. Likewise it counts the arrangements with three increments of overlap three times, and so on. Thus the product of lengths represents an overestimation of the number of intrinsic arrangements with overlap. |
|
|
|
But suppose we fix two particular consecutive increments on the circle and require that all the spans contain both of them. The number of arrangements that satisfy this requirement is obviously the product (m1 – 1)(m2 – 1)...(mn – 1). This counts the arrangements with two increments of overlap only once, and it counts the arrangements with three increments of overlap twice, and so on. Therefore, if we subtract this product from the previous product, the result counts the number of arrangements with any number of increments of overlap exactly once. Hence the number of such arrangements is |
|
|
|
|
|
|
|
It follows that the probability of overlap for these n spans placed randomly around the unit circle is |
|
|
|
|
|
|
|
For example, with n = 3 the result is |
|
|
|
|
|
|
|
Obviously if we hold the ratios w1 = m1/N, w2 = m2/N, and w3 = m3/N constant and increase N, all the terms in the numerator of degree less than two drop out, and we're left with the result for the continuous case |
|
|
|
|
|
|
|
In general for n spans of lengths w1, w2, .., wn randomly distributed uniformly around a circle of unit circumference, with the condition that the sum w1 + w2 + ... + wn is less than 1, the probability of some common overlap among all n of the spans is |
|
|
|
|
|
|
|
Now let's return to our original problem, to find the probability of meeting between n people with distinct waiting times in a fixed interval. Again we can start with the discrete case, and then go over to the continuous case at the end. We divide the unit interval into N segments, and let the integer mj for j = 1,2,..,n denote the waiting times (corresponding to Nwj), arranged so that 1 ≤ m1 ≤ m2 ≤ ... ≤ mn ≤ N. We apply the same reasoning as in the case of the circle, except that now each fixed segment of overlap must be treated separately, because the segments near the starting time are truncated by the boundary. For example, the first waiting interval m1 has only one position that includes the first segment, and it has only two positions that overlap with the second segment, and so on. Only when we reach segments more than mj from the boundary are there mj intersecting positions. In general, the number of positions of the kth waiting interval that intersect with the jth segment is min(j,mk). Hence, instead of having N times the product of the mk values, we must evaluate the sum over j from 1 to N of the products of the min(j,mk) values. Of course, as in the case of the circle, this represents an over-estimate, because if counts each configuration multiple times. As before, this is corrected by subtracting the products of the quantities [min(j,mk) – 1]. |
|
|
|
Consequently, the probability of meeting for n people with waiting times m1, m2, ..., mn is given by |
|
|
|
|
|
|
|
After expanding the products, the terms of degree n cancel, leaving only terms of degree n-1 and lower. Bringing 1/Nn-1 in from the leading factor, and letting wj and t denote the ratios mj/N and j/N respectively, the resulting expression is purely a function of the wj and the variable t, plus terms divided by some power of N. The latter vanish in the limit as N goes to infinity, so only the terms of degree n–1 remain. (These are comprised of the n products of n–1 elements of the set min(j,mj), j = 1,2,..,n.) In the continuous limit, the summation over the index j can be evaluated as an integration over the variable t. Noting that dj = Ndt, the remaining power of 1/N in the leading factor is cancelled, and we have in the continuous limit |
|
|
|
|
|
|
|
where sn-1(x1,x2,..,xn) denotes the sum of all products of n–1 arguments. Splitting up this integral into the ranges from 0 to w1, from w1 to w2, and so on, we can eliminate the min functions and write this as a sum of elementary integrals. To simplify the expressions, it's convenient to define the following symbols for the kth and (k-1)th symmetric functions of the k smallest waiting times: |
|
|
|
|
|
|
|
with π0 = 1 and σ0 = 0. Also, let w0 = 0 and wn+1 = 1. In terms of these parameters we can write |
|
|
|
|
|
|
|
Evaluating the integrals, this becomes |
|
|
|
|
|
|
|
In view of the identity πj+1 = πj wj+1, the argument of the first summation can be written as |
|
|
|
|
|
|
|
Hence these terms constitute a telescoping sequence, with the net sum πn. Therefore, we have the result |
|
|
|
|
|
|
|
Notice that this formula reduces to equation (1) if all the waiting times are equal. Also, it's easily verified that this formula gives the results previously derived for n = 2 and n = 3. For another illustration, consider the case n = 4. Using this expression, the probability of all parties meeting is |
|
|
|
|
|
|
|
Inserting the explicit expressions for the symmetric functions, and simplifying, this gives the formula |
|
|
|
|
|
|
|
To give the explicit formula more directly, the summation in equation (2) can be made more explicit if we collect terms by wj. This gives |
|
|
|
|
|
|
|
Making use of the identity σj+1 = wj+1σj + πj, the summation splits into a sum over the πj and a sum over the σj as follows |
|
|
|
|
|
|
|
The argument of the first summation when j = n–1 is simply wnπn-1 = πn, so this cancels with the leading πn term. Also, since σ1 = π0 = 1, we can bring the term involving w1 into the first summation, shift the indices, and combine one power of wj with πj-1, to give the result |
|
|
|
|
|
|
|
(For comparison, recall that the circular case gave simply Pn = σn.) Each σj represents j terms, so the total number of terms (i.e., individual products) in Pn is |
|
|
|
|
|
|
|
However, even though the number of terms increases as the square of n, the computation of Pn can be completed in O(n) steps, because the σj quantities can be computed recursively in O(n) steps. |
|
|
|
The other patterns of intersection that can arise when n intervals of various lengths are placed with their starting points on the unit interval are discussed in Meeting Combinations and Interval Graphs. The probabilities of these combinations in the case of equal intervals are derived in Probability of Intersecting Intervals. |
|
|